

很多小伙伴在跟着视频学习爬虫的时候总是能完成一个爬虫,但自己独立开发就开发不了,原因是自己并没有网页分析的能力,不懂得如何从网页中获取相应的数据,更有甚者连网络分析的能力都没有,请求页面总是被服务器拒绝。实际上浏览器为我们提供的F12开发者工具是一个非常不错的网页分析和网络分析的工具。接下来我们就来讲讲如何用F12开发者工具进行网页和网络分析吧。
网页分析
爬虫的目的,就是从网页中获取到某一元素的某个值,这一点其实很简单,只要能定位到元素就可以获取到它的值了。在小编的自动化测试开发辅助工具——F12开发者工具介绍!中介绍了如何定位元素,在文末也介绍了另一种定位方式——css定位,实际上在python中有一个库叫beautifulsoup,这个库可以通过css来定位元素并获取它的值,各位小伙伴可以前往beautifulsoup教程进行学习。
另一个更加出名的xml解析库叫lxml,这个库不止可以通过css定位元素,也可以用想xpath来进行定位,详情可以看:lxml教程
网络分析
爬虫的基本动作第一步就是向服务器发起请求并获取响应,然后才是对响应的处理,因为响应一般对应的是页面的HTML代码,所以网页分析的作用在这里体现。然而爬虫请求服务器一般都会被发现,因为爬虫没有请求头的掩护(相当于直接告诉浏览器我是爬虫),在F12开发者工具中有一项网络功能,它可以记录页面和服务器之间的请求和响应。
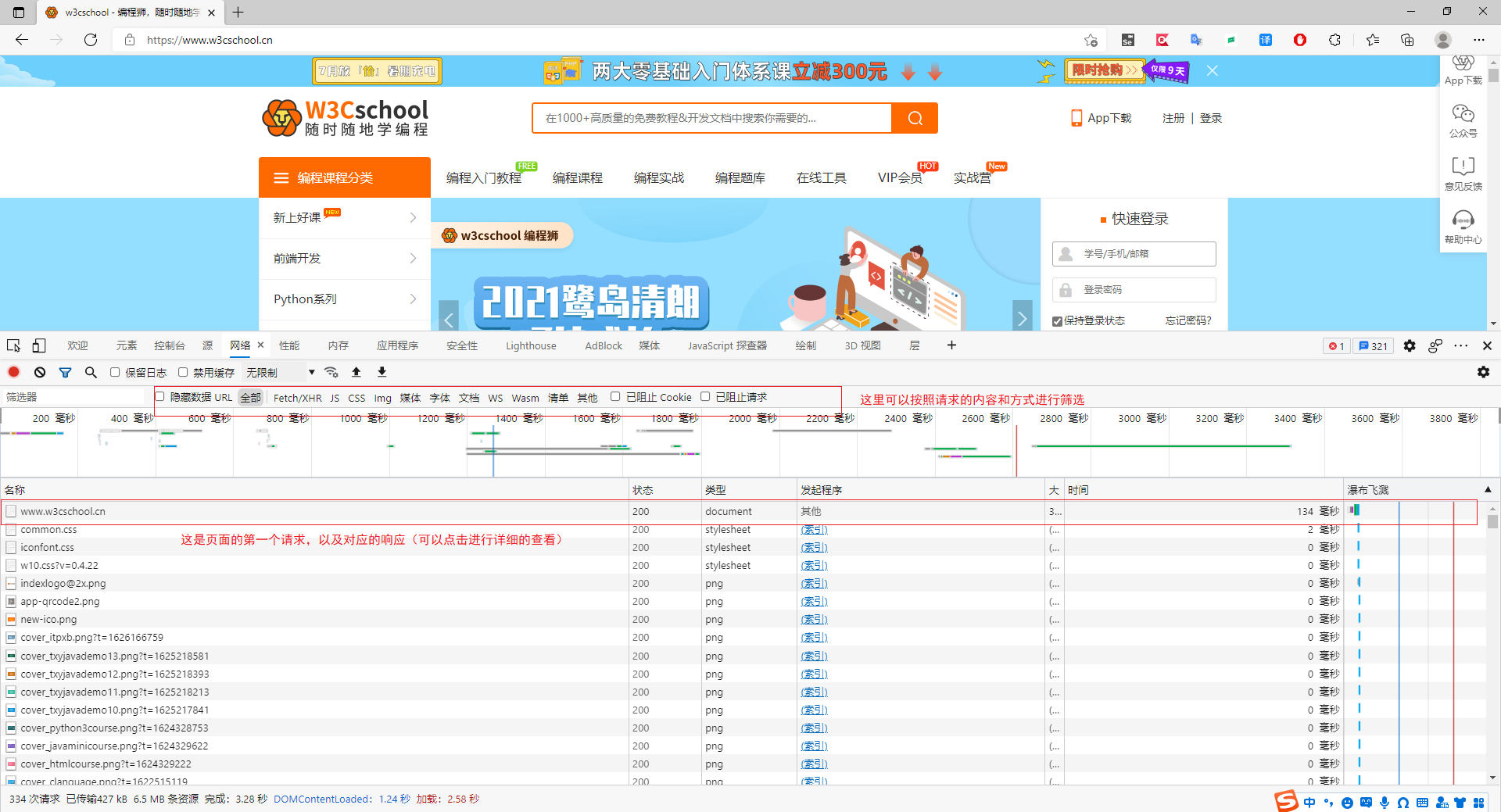
点击即可看到详细的信息:
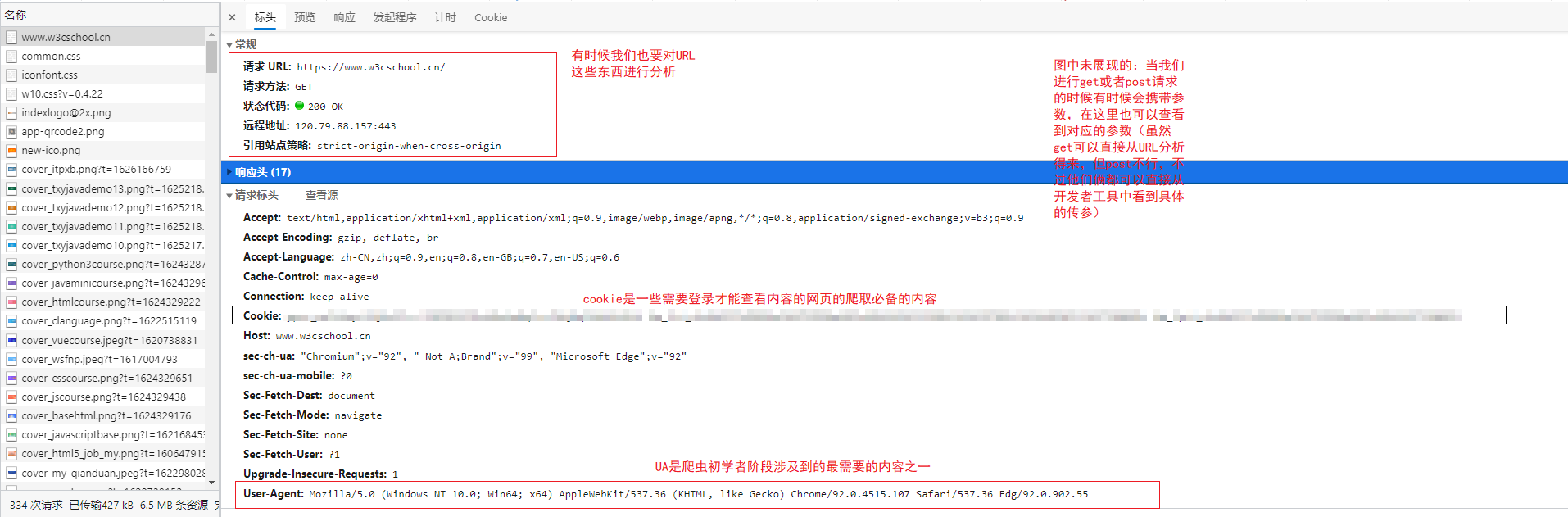
从请求和返回的响应中我们可以获得很多内容,在上述图中已有注明,主要对爬虫开发有关的有cookie,浏览器的user-agent,请求时传递的参数和请求url分析等。其实这个工具还给我们提供了很多内容,但小编水平有限只能用这么多,小伙伴们可以继续往深处挖掘。
小结
对于爬虫开发而言,网络分析和网页分析才是爬虫开发的要点,python代码编程只是实现爬虫的方式罢了。如果你还学不会爬虫编程,请好好思考你是否已经学会了网络分析和网页分析。或者更简单地:你是否学会了使用F12开发者工具。以上就是这篇文章的全部内容了,更多F12开发者工具的其他有用的内容可以关注W3Cschool的后续内容,小编在这里等着你!



