

编程语言分为面向过程编程、函数式编程和面向对象编程。其实 python 就是一种面向对象编程,那么我们先了解一下它们的特点和优缺点以及它们的区别是什么。
面向过程编程:“面向过程”(Procedure Oriented)是一种以过程为中心的编程思想。这些都是以什么正在发生为 目标进行编程,不同于面向对象的是谁在受影响。与面向对象明显的不同就是封装、继承、类。
面向过程编程最易被初学者接受,其往往用一长段代码来实现指定功能,开发过程的思路是将数据与函数按照执行的逻辑顺序组织在一起,数据与函数分开考虑。
- 特性:模块化 流程化
- 优点:性能比面向对象高,因为类调用时需要实例化,开销比较大,比较消耗资源;单片机、嵌入式开发、Linux/Unix 等一般采用面向过程开发,性能是最重要的因素。
- 缺点:没有面向对象易维护、易复用、易扩展
函数式编程: 函数式编程也是种编程方式,它将电脑运算视为函数的计算。函数编程语言最重要的基础是λ演算(lambda calculus),而且 λ 演算的函数可以接受函数当作输入(参数)和输出(返回值)。
它的主要思想是把运算过程尽量写成一系列嵌套的函数调用。
Python 不是也不大可能会成为一种函数式编程语言,但是它支持许多有价值的函数式编程语言构建。也有些表现得像函数式编程机制但是从传统上也不能被认为是函数式编程语言的构建。
Python内建函数 : filter()、map()、reduce()、max()、min()
面向对象编程:面向对象是按人们认识客观世界的系统思维方式,采用基于对象(实体)的概念建立模型,模拟客观世界分析、设计、实现软件的办法。通过面向对象的理念使计算机软件系统能与现实世界中的系统一一对应。
面向对象编程可以将数据与函数绑定到一起,进行封装,这样能够更快速的开发程序,减少了重复代码的重写过程。
- 特性:抽象 封装 继承 多态
- 优点:易维护、易复用、易扩展,由于面向对象有封装、继承、多态性的特性,可以设计出低耦合 的系统,使系统更加灵活、更加易于维护
- 缺点:性能比面向过程低
可以拿生活中的实例来理解面向过程与面向对象,例如五子棋,面向过程的设计思路就是首先分析问题的步骤:1、开始游戏,2、黑子先走,3、绘制画面,4、判断输赢,5、轮到白子,6、绘制画面,7、判断输赢,8、返回步骤2,9、输出最后结果。把上面每个步骤用不同的方法来实现。
如果是面向对象的设计思想来解决问题。面向对象的设计则是从另外的思路来解决问题。整个五子棋可以分为1、黑白双方,这两方的行为是一模一样的,2、棋盘系统,负责绘制画面,3、规则系统,负责判定诸如犯规、输赢等。第一类对象(玩家对象)负责接受用户输入,并告知第二类对象(棋盘对象)棋子布局的变化,棋盘对象接收到了棋子的变化就要负责在屏幕上面显示出这种变化,同时利用第三类对象(规则系统)来对棋局进行判定。
可以明显地看出,面向对象是以功能来划分问题,而不是步骤。同样是绘制棋局,这样的行为在面向过程的设计中分散在了多个步骤中,很可能出现不同的绘制版本,因为通常设计人员会考虑到实际情况进行各种各样的简化。而面向对象的设计中,绘图只可能在棋盘对象中出现,从而保证了绘图的统一。
面向对象编程三大特性
在看面向对象编程三大特性之前,先了解一下对象和类的区别。
对象和类
类(Class)是现实或思维世界中的实体在计算机中的反映,它将数据以及这些数据上的操作封装在一起。类实际上是创建实例的模板。
对象(Object)是具有类类型的变量。类和对象是面向对象编程技术中的最基本的概念。 而对象就是一个一个具体的实例。
定义类的方法:
class 类(): pass
那么如何将类转换成对象呢?
实例化是指在面向对象的编程中,把用类创建对象的过程称为实例化。是将一个抽象的概念类,具体到该类实物的过程。实例化过程中一般由类名 对象名 = 类名(参数1,参数2...参数n)构成。
定义类之后一般会用到构造方法 init 与其他普通方法不同的地方在于,当一个对象被创建后,会立即调用构造方法(也称为魔术方法)。自动执行构造方法里面的内容。
1.封装特性
封装,顾名思义就是将内容封装到某个地方,以后再去调用被封装在某处的内容。 所以,在使用面向对象的封装特性时,需要:
- 将内容封装到某处
- 从某处调用被封装的内容,调用方法如下:
- 通过对象直接调用被封装的内容: 对象.属性名
- 通过 self 间接调用被封装的内容: self.属性名
- 通过 self 间接调用被封装的内容: self.方法名()
对于面向对象的封装来说,其实就是使用构造方法将内容封装到 对象 中,然后通过 对象直接或者 self 间接获取被封装的内容。
具体例子如下:
# 1). 类的定义
class People:
# 构造方法(魔术方法): 当创建对象时会自动调用并执行;
# self实质上是实例化出来的对象, e.g: xiaoming, xiaohong;
def __init__(self, name, age, gender):
# print("正在创建对象")
# print(self) # 实质上是一个对象
# 将创建对象的属性(name, age, gender)封装到self(就是实例化的对象)变量里面;
# 在类里面定义的变量: 属性
self.name = name
self.age = age
self.gender = gender
# 在类里面定义的函数: 方法
def eat(self):
print('%s eating......' %(self.name))
def sleep(self):
# 获取对象self封装的属性(name, age, gender)
print('%s sleep.......' %(self.name))
# 2). 实例化: 通过类实现对象的创建
xiaoming = People("小明", 20, '男')
# 将对象self/xiaoming封装的属性(name, age, gender)从里面拿出来;
print(xiaoming.name)
xiaoming.eat()
xiaoming.sleep()
xiaohong = People("小红", 20, '女')
print(xiaohong.name)
xiaohong.eat()
xiaohong.sleep()
2、继承特性
1)继承
继承描述的是事物之间的所属关系,当我们定义一个 class 的时候,可以从某个现有的 class 继承,新的 class 称为子类、扩展类(Subclass),而被继承的class称为基类、父类或超类(Baseclass、Superclass)。
问题一:如何实现继承呢?
子类在继承的时候,在定义类时,小括号( )中为父类的名字,例如: class son(father): 这里father就是son的父类。
问题二:继承的工作机制是什么?
父类的属性、方法,会被继承给子类。 举例如下:如果子类没有定义 init 方法,父类有,那么在子类继承父类的时候这个方法就被继承了,所以只要创建对象,就默认执行了那个继承过来的 init 方法。
重写父类方法:就是在子类中,有一个和父类相同名字的方法,那么在子类中的方法就会覆盖掉父类中同名的方法,就实现了对父类方法的重写。
调用父类的方法:
- 在子类中,直接利用 父类名.父类的方法名()
- super() 方法: python2.2+的功能,格式为: super(子类名称, self).父类的方法名() (建议用此方法)
2)多继承
多继承,即子类有多个父类,并且具有它们的特征。
新式类与经典类的区别:
在 Python 2及以前的版本中,由任意内置类型派生出的类,都属于“新式类”,都会获得所有“新式类”的特性;反之,即不由任意内置类型派生出的类,则称之为“经典类”。
新式类:
class 类名(object):
pass
经典类:
class 类名:
pass
“新式类”和“经典类”的区分在 Python 3之后就已经不存在,在 Python 3.x之后的版本,因为所有的类都派生自内置类型 object(即使没有显示的继承 object 类型),即所有的类都是“新式类”。
它们两个最明显的区别在于继承搜索的顺序不同,即:
经典类多继承搜索顺序(深度优先算法):先深入继承树左侧查找,然后再返回,开始查找右侧。
新式类多继承搜索顺序(广度优先算法):先在水平方向查找,然后再向上查找。
图示如下:
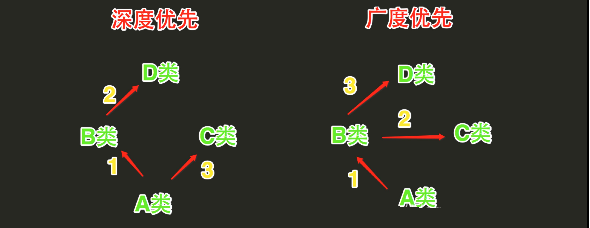
具体例子如下:
# python2:
# 经典类: class Father:
# 新式类: class Father(object):
# python3:
# 所有的都是新式类
# 新式类: 广度优先
# 经典类: 深度优先
class D:
a = 'd'
class B(D):
pass
class C(D):
a = 'c'
class A(B, C):
pass
obj = A()
print(obj.a)运行结果是 c,由此可见为广度优先搜索的结果。
3)私有属性与私有方法
默认情况下,属性在 Python 中都是“public”, 大多数 OO (面向对象)语言提供“访问控制符”来限定成员函数的访问。
在 Python 中,实例的变量名如果以 __ (双下划线)开头,就变成了一个私有变量/属性(private),实例的函数名如果以 __ 开头,就变成了一个私有函数/方法(private)只有内部可以访问,外部不能访问。
那么私有属性一定不能从外部访问吗?
python2版本不能直接访问 属性名,是因为 Python 解释器对外把 属性名 改成了 _类名属性名 ,所以,仍然可以通过 _类名属性名 来访问 属性名 。 但是不同版本的 Python 解释器可能会把 属性名 改成不同的变量名,因此不建议用此类方法访问私有属性。
私有属性和方法的优势:
- 确保了外部代码不能随意修改对象内部的状态,这样通过访问限制的保护,代码更加健壮。
- 如果有要允许外部代码修改属性怎么办?可以给类增加专门设置属性方法。 为什么大费周折?因为在方法中,可以对参数做检查,避免传入无效的参数。
具体实例如下:
class Student(object):
__country = 'china'
def __init__(self, name, age, score):
self.name = name
# 年龄和分数是私有属性
self.__age = age
self.__score = score
# 私有方法, 只能在类内部执行;
def __modify_score(self, scores):
self.__score = scores
print(self.__score)
def set_age(self, age):
if 0<age <150:
self.__age = age
print("当前年龄:", self.__age)
else:
raise Exception("年龄错误")
def set_score(self, scores):
if len(scores) == 3:
self.__score = scores
else:
raise Exception("成绩异常")
class MathStudent(Student):
pass
student = Student("Tom", 10, [100, 100, 100])
# 在类的外部是不能直接访问的;
print(student.name)
student.set_age(15)
# Python 解释器对外把 __属性名 改成了 _类名__属性名
# print(student._Student__age)3.多态特性
多态(Polymorphism)按字面的意思就是“多种状态”。在面向对象语言中,接口的多种不同的实现方式即为多态。通俗来说: 同一操作作用于不同的对象,可以有不同的解释,产生不同的执行结果。
多态的好处就是,当我们需要传入更多的子类,只需要继承父类就可以了,而方法既可以直接不重写(即使用父类的),也可以重写一个特有的。这就是多态的意思。调用方只管调用,不管细节,而当我们新增一种的子类时,只要确保新方法编写正确,而不用管原来的代码。这就是著名的“开放封闭”原则:
- 对扩展开放(Open for extension):允许子类重写方法函数
- 对修改封闭(Closed for modification):不重写,直接继承父类方法函数



