

本文转载至知乎ID:Charles(白露未晞)知乎个人专栏
本文转载至知乎ID:Charles(白露未晞)知乎个人专栏
下载W3Cschool手机App,0基础随时随地学编程>>戳此了解
导语
下载W3Cschool手机App,0基础随时随地学编程>>戳此了解
偶遇了一篇文章:
“Mapping Your Music Collection”
https://www.christianpeccei.com/musicmap/
感觉颇有缘分,似有命中注定之感,于是想着用一些简单的音频处理、机器学习和可视化技术,简单地分析一下自己的音乐收藏。当然我对乐理知识一无所知,所以分析将不涉及任何与乐理知识相关的内容,纯属“瞎玩”性质的分析。T_T
那么就让我们愉快地开始吧~~~
相关文件
百度网盘下载链接: https://pan.baidu.com/s/16lZb3JbHeC__k_oP8RMXUg
密码: nxpt
相关工具
Python版本:3.6.4
相关模块:
numpy模块;
sklearn模块;
matplotlib模块;
以及一些Python自带的模块。
mpg123:
1.25.10
环境搭建
安装Python并添加到环境变量,pip安装需要的相关模块;
将相关文件中提供的mpg123.zip文件解压后添加到环境变量中,例如:
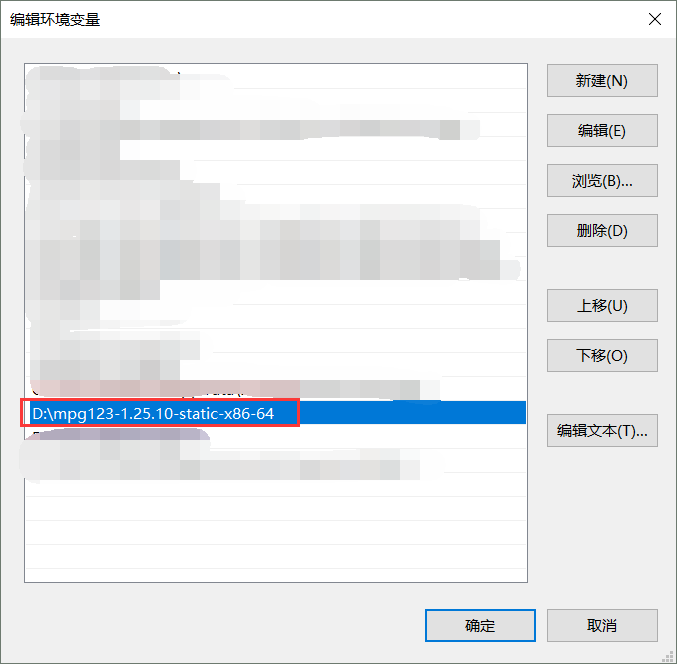
开始分拆
方便起见,所有的音乐文件均先转为.wav格式后再做分析。
从最简单的开始吧!让我们先来看看不同歌手的声音波形图:
周杰伦:
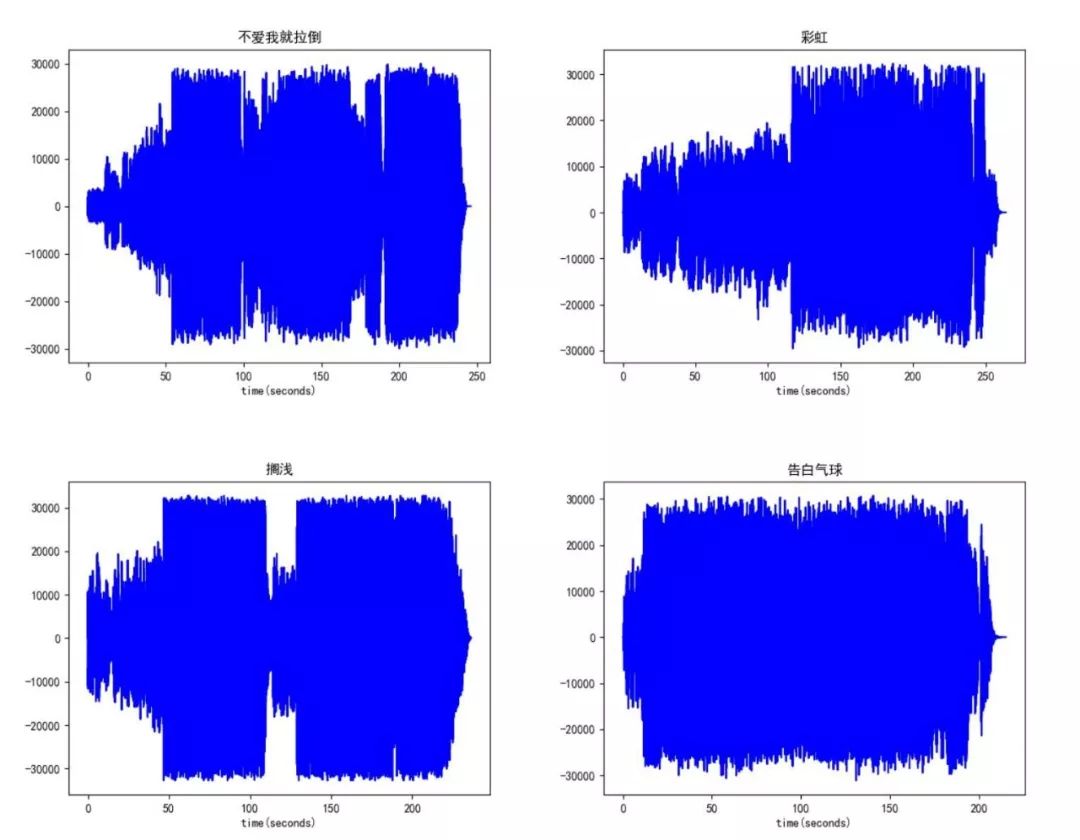
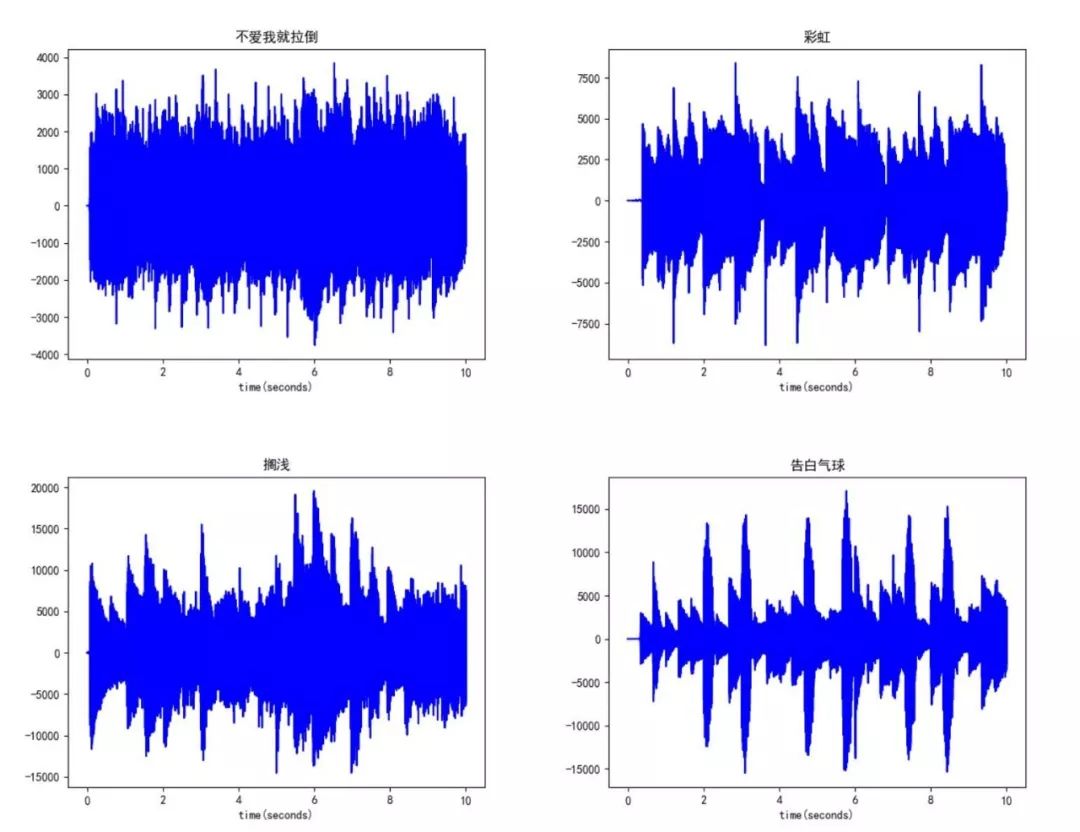
感觉波形图好混乱,似乎是数据量太大引起的,于是我打算换一个策略,只画出每首歌曲前10秒的波形图来作比较,毕竟良好的开端是成功的一半?
周杰伦:
许嵩:
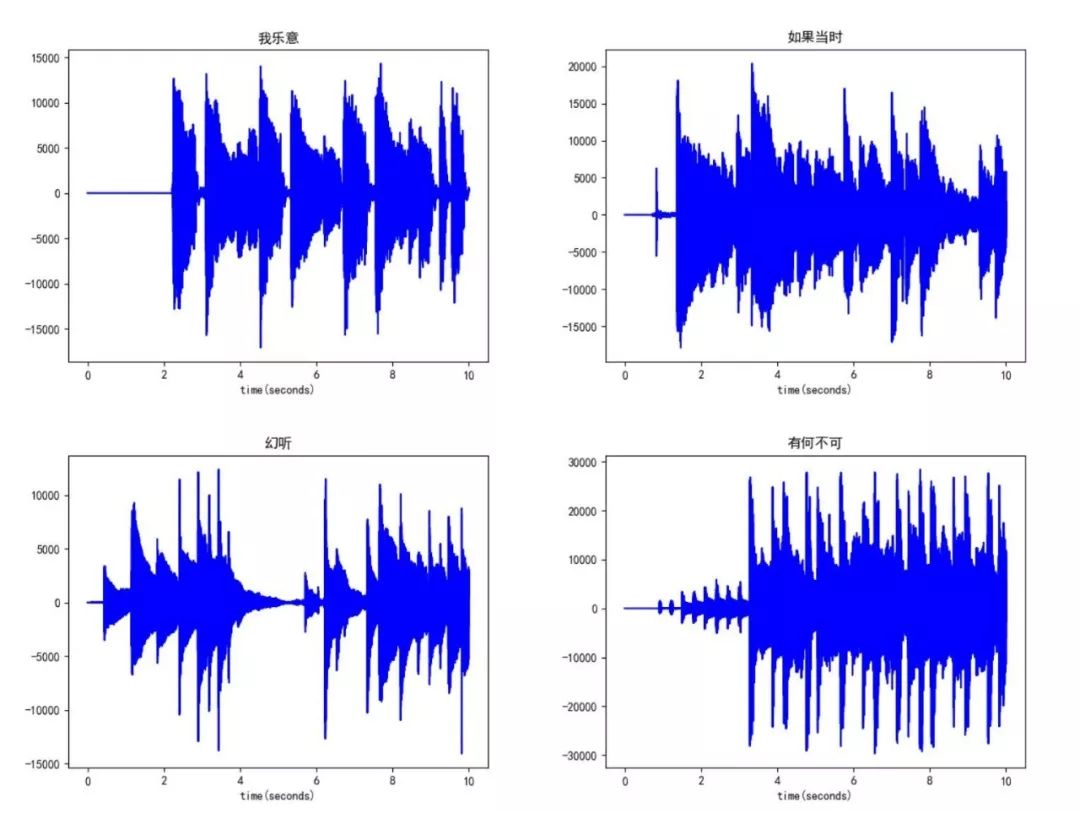
陈奕迅:
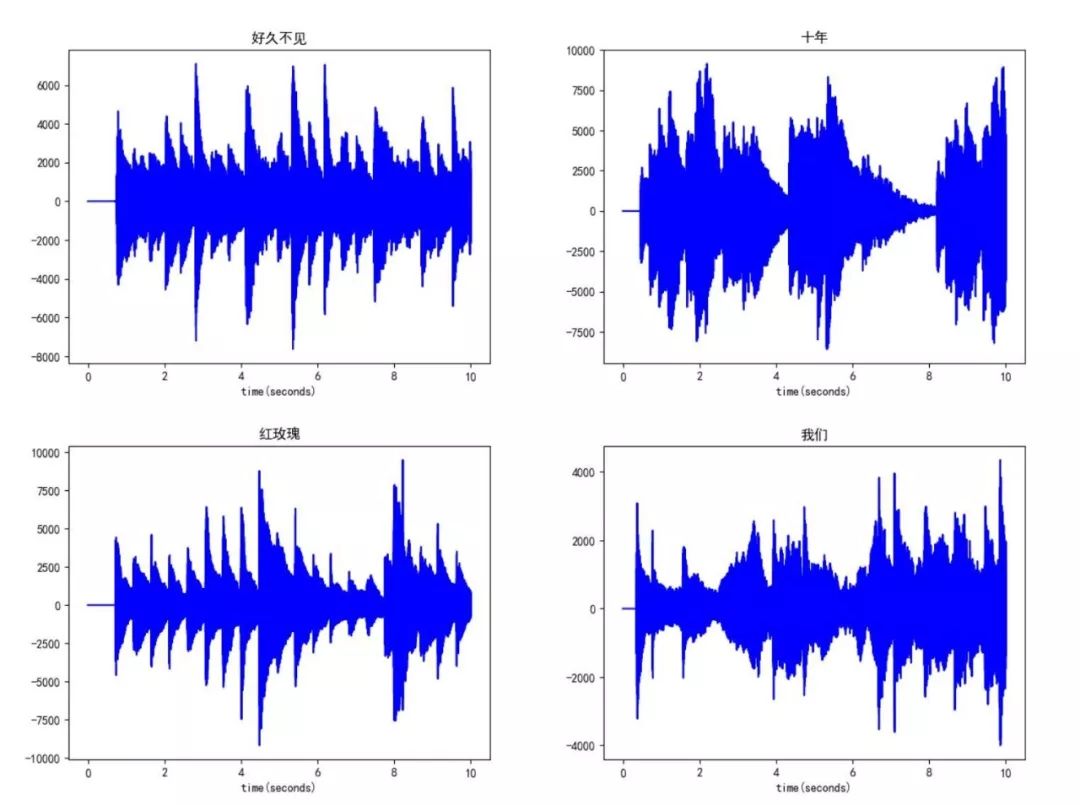
Interesting...
好像还是挺有意思的,但并看不出什么端倪来的样子,同一个歌手唱的歌的波形结构之间的差异和不同歌手唱的歌的波形结构之间的差异仿佛都挺大的。虽然并没有规定说同一个歌手唱的歌的波形结构之间的差异一定很小,不同歌手唱的歌的波形结构之间的差异一定很大。
好吧,有些混乱,还是随意点的好。那么我们来尝试性地提取一下歌曲的特征吧。我们打算提取的歌曲特征有:
① 歌曲波形的统计矩,包括均值、标准差、偏态和峰态,同时,我们通过平滑窗(递增平滑,长度分别为1,10,100,1000)来获取这些特征在不同时间尺度上的表现;
② 为了体现信号的短时变化,我们可以计算一下波形一阶差分幅度的统计矩,同样也通过平滑窗来获取这些特征(均值、标准差、偏态和峰态)在不同时间尺度上的表现;
③ 最后,我们计算一下波形的频域特征,这里我们只计算歌曲在不同频段(将整个频段均分为10份)的能量占比,不过直接对歌曲的波形数据作快速傅里叶变换的话其计算量过于庞大了,因此先让波形数据通过长度为5的平滑窗再对其作快速傅里叶变换。
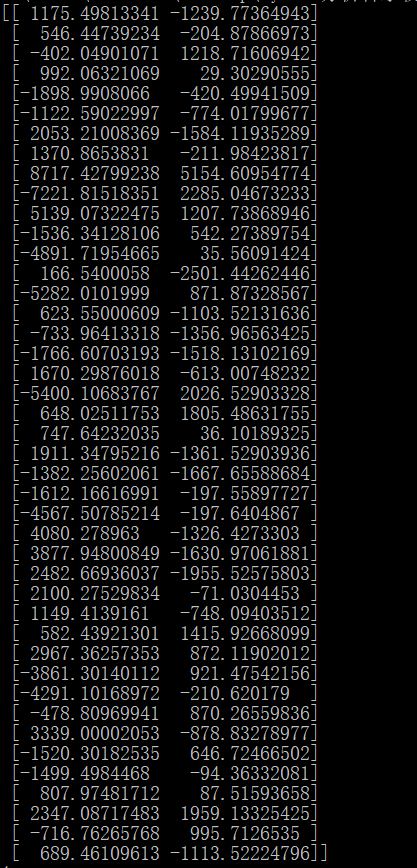
综上所述,我们已经获得了歌曲的42个特征值。下面我们尝试利用这些特征值对我这几天下载的43首歌曲进行k均值聚类。首先,为了便于结果的可视化,我们利用PCA对数据进行降维(42维特征到2维特征),为了方便起见,我们直接调库(sklearn)实现,结果打印如下:
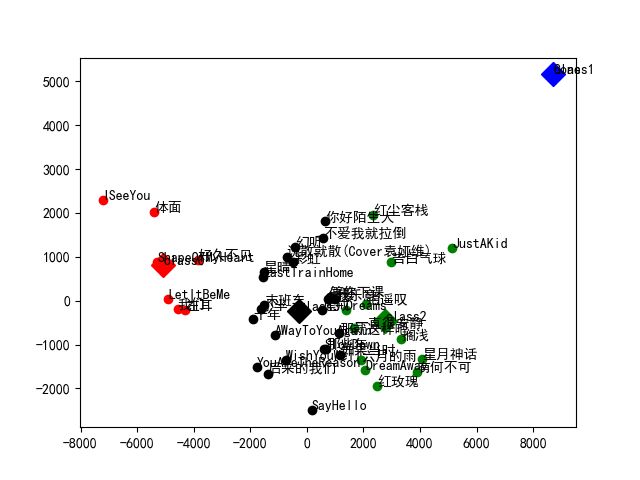
OK,接下来我们就可以对降维后的数据进行聚类了,这里我们将自己实现一下k均值聚类算法而不是简单地调库,最终的聚类结果如下图所示(k=4):
接下来我们尝试先对歌曲的42个特征值进行归一化处理,然后再进行上面的PCA和聚类操作,同时令k=3,最终的聚类结果如下图所示:
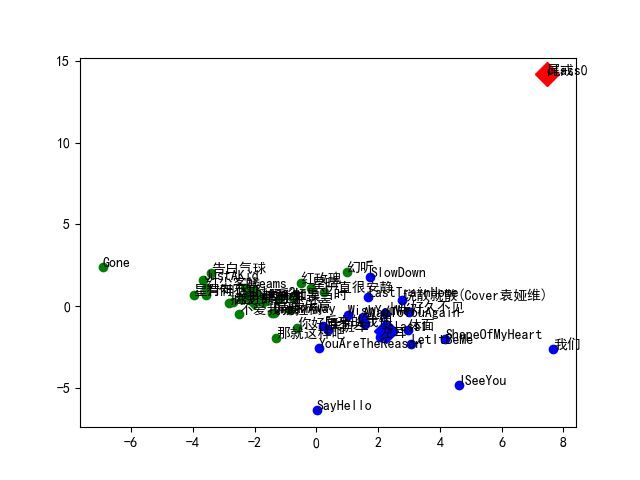
Emmm,好像效果更差了。
不过我发现我喜欢了8年的歌“尾戒”竟然一枝独秀了!还是很棒的,哈哈~~~
当然,这里有一个问题,歌曲的42个特征值是人工选取的,也许并不很好的表现出歌曲特征,且这些特征之间的相关系数是不为0的,也就是存在冗余特征。
https://www.christianpeccei.com/musicmap/一文利用了遗传算法从42个特征值中筛选出了18个特征值作为歌曲最终的特征向量,其结果如下:

懒得复现了,直接用他的结论重新进行聚类,结果如下(k=3):
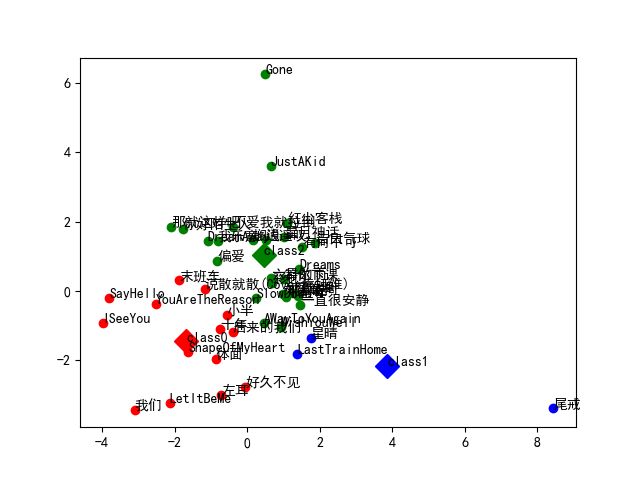
Emmm,好像半斤八两。
那就这样吧,就当学点基础的音频处理、机器学习和可视化技术了。
所有源代码和素材均在相关文件中提供了,End。



